CPU Scheduling introduction
Concept, what you need to know before, real-world usage, (6 minute reading)
CPU scheduling is the basis of multiprogrammed operating systems. By switching the CPU among processes, the operating system can make the computer more productive (page 266 from this book)
The idea is similar to average wait time [Leetcode example], namely we want to minimize the waiting time of the process to be executed on our available hardware. There are some criteria we need to consider first before implementing a scheduling algorithm:
Scheduling Criteria
- CPU utilization. Keep the CPU as busy as possible. (
maximize) - Throughput. How many processes are completed per time unit. (
maximize) - Turnaround time. How long does it take to run a process. Calculated as the sum of the periods spent waiting in the
ready queue + executing on CPU + doing I/O. (
minimize) - Waiting time. Amount of time waiting in ready queue. (
minimize) - Response. Time it takes to start responding. (first time on CPU) (
minimize)
Prerequisite knowledge
An early intuition to resolve this problem is to think it as a FIFO (First In First Out), but in order to minimize the average time we need other algorithms and other ways to keep our data.
First, we need to learn what a burst duration is, what is a preemptive, nonpreemptive scheduler and what a dispatcher is.
Burst duration
Process execution consists of a cycle of CPU execution and I/O wait. Processes alternate between those 2 states. An example is shown in this figure.
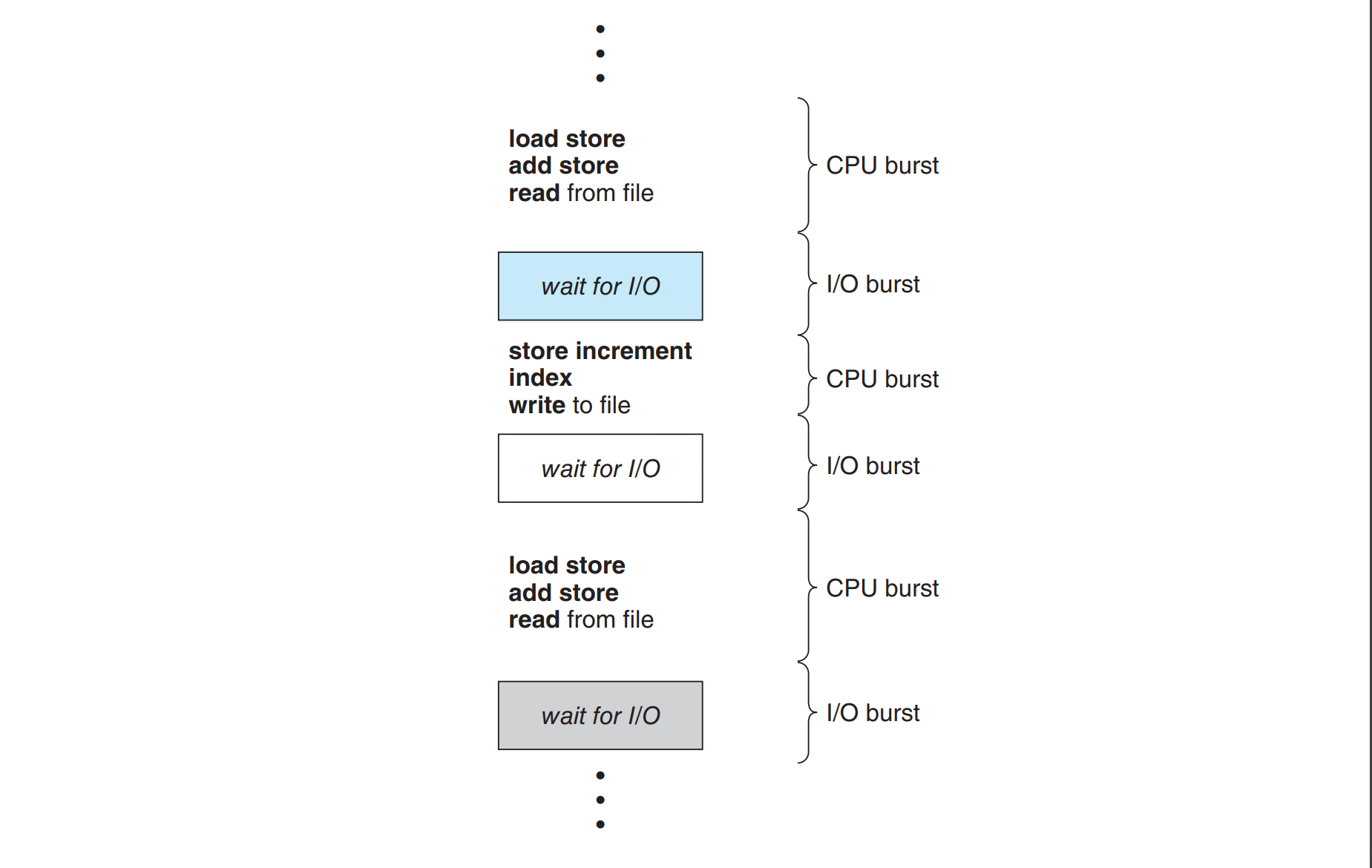
The burst duration is essential for letting the scheduling algorithm know how much time will take for a specific process to run. But how do we know the duration before running it?
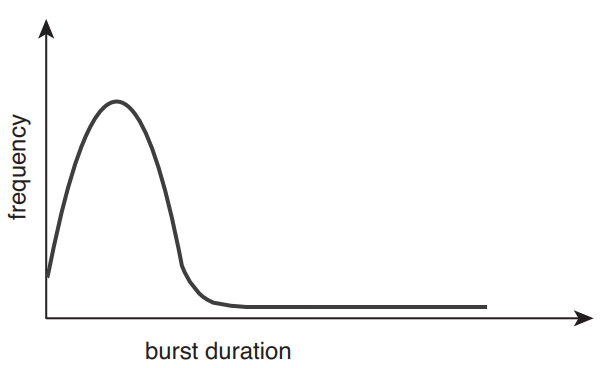
Solution 1 - Look at the frequency curve.
The durations of CPU bursts have been measured extensively, thus we can predict the average burst time.
Solution 2 - Predict the next cpu burst
We expect that the next CPU burst will be similar in length to the previous ones.
The next CPU burst is predicted as an exponential average of the measured length of previous CPU bursts.
- tn = actual length of n^th CPU burst.
- Tn+1 = predicted value for next CPU burst
- Tn = last guess
- For alpha,
0 <= alpha <= 1:tn+1 = alpha * tn + (1 - alpha) * Tn
Generalized :tn+1 = alpha * tn + ... + (1 - alpha)^j * alpha * Tn-j + ... + (1 - alpha)^ (n + 1) * T0
We can choose alpha = 1/2 : recent history and past history are equally weighted. Example :
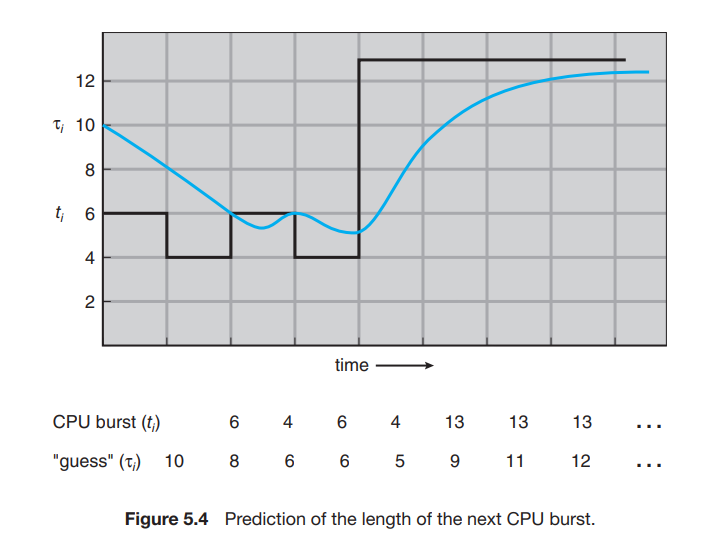
T0 = 10, t1 = 6. alpha = 1/2
T1 = 1/2 _ 6 + (1 - 1/2) _ 10 = 8
T2 = 1/2 _ 4 + (1 - 1/2) _ 8 = 6
T3 = 1/2 _ 6 + (1 - 1/2) _ 6 = 6
...
Preemptive and Nonpreemptive Scheduling
CPU scheduling decisions may take place when a process:
- Switches from running to waiting state (e.g. wait() for the child in parent)
- Switches from running to ready state (e.g. when interrupt occurs)
- Switches from waiting to ready (e.g. at completion of I/O)
- Terminates
1 & 4 => nonpreemptive
All of them => preemptive
Under nonpreemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases either by terminating or by switching to the waiting state.
Whereas, preemptive scheduling, can change between processes multiple times until they finish.
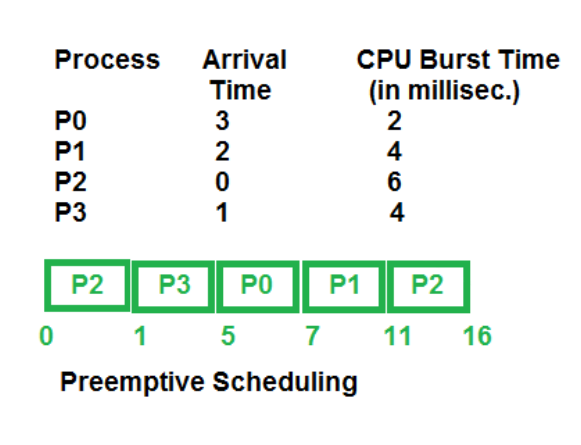
Question : We talked about processes, but what about kernel mode? When we do a syscall the processes
interrupts and waits a response from kernel (read, open file, etc.). Is this task preemptive, or not?
(For the answer you can read the pages 202 and 262 from this book)
Moreover, for a better understanding, on the website you'll find a useful table comparing preemptive and non-preemptive scheduling
Dispatcher latency
The dispatcher is the module that gives control of the CPU’s core to the process selected by the CPU scheduler. The time it takes for the dispatcher to stop one process and start another running is known as the dispatch latency.
For every context switch, the dispatcher is invoked.
You can see how many context switches a process had. See here.
Also, with vmstat 1 3 you can see the total context switches over a 3-second period. (in system column, below cs)
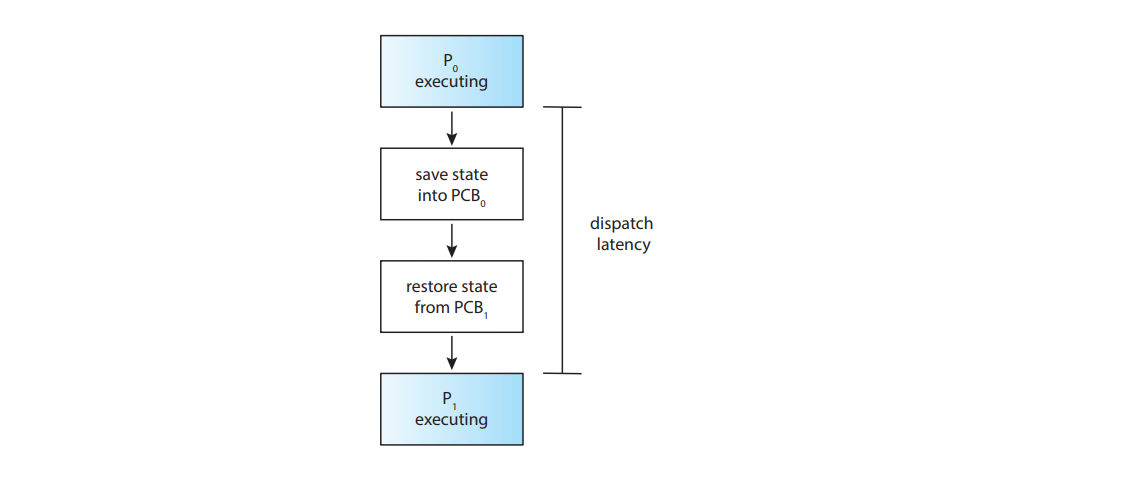
When is a process switched?
Below, it will be shown when a process stops running on the CPU:
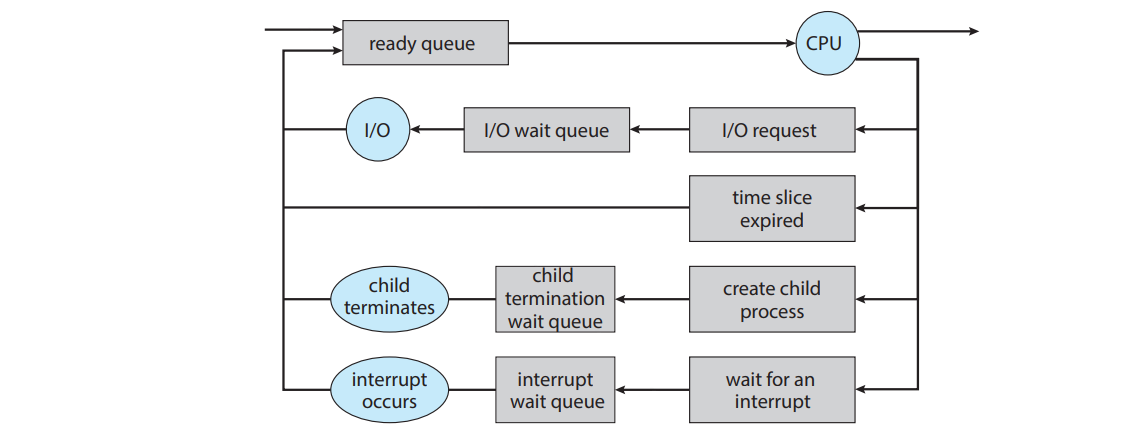
More could be read at page 113
Examples of scheduler usage
- used in Embedded Systems and Real-Time Systems:
- In real-time systems, tasks must meet strict timing constraints (e.g., airbag deployment in cars). CPU scheduling principles are applied in these systems to ensure critical tasks are completed on time.
- High-Performance Computing (HPC) and Parallel Processing
- In HPC, multiple tasks need to be scheduled across many cores or even multiple computers. CPU scheduling concepts help allocate tasks efficiently, balancing loads and minimizing idle times.
- Mobile Application Development
- Mobile devices have limited resources, so efficient scheduling is critical to avoid battery drain and maintain performance. Mobile OS schedulers prioritize tasks based on CPU, GPU, and memory usage.
- this article that talks about a scheduler for power-efficient smartphones
Extreme example YouTube:
We can think about the YouTube scheduling recommendation algorithm as analogy for CPU scheduling. Now, let's take each criteria and convert it in YouTube mindset.
- CPU utilization → User Engagement
In CPU scheduling, maximizing CPU utilization ensures that the processor is busy most of the time, making efficient use of resources. For YouTube’s recommendation algorithm, this translates to maximizing user engagement, which involves keeping users watching videos for extended periods. - Throughput → Recommended Video Volume
Throughput in CPU scheduling refers to the number of processes completed in a given time frame. For YouTube’s algorithm, this becomes the number of videos recommended and watched within a session or a certain time period. - Turnaround Time → Viewer Satisfaction Rate
In CPU scheduling, turnaround time is the total time taken to complete a process. For YouTube, we can relate this to the viewer satisfaction rate, which is how quickly users find content they enjoy. If users quickly find engaging videos, it indicates an effective algorithm. - Wait Time → Recommendation Delay Wait time in CPU scheduling is the time a process spends waiting to be executed. On YouTube, this can be thought of as the delay before an appealing recommendation appears. Ideally, users should see engaging content immediately or soon after starting a session.
- Response Time → Immediate User Interaction
In CPU scheduling, response time is the time it takes for the system to start responding to a process. On YouTube, this relates to how quickly users interact with a video (clicking on it, watching, or taking some other action).
Philosophical questions
Can two processes running slightly different programs concurrently halt at the same physical address? If no, why? If yes, give example.
Can we interrupt an I/O operation?
Follow-up : If we can, where do we store the values from the kernel operations at context switch? solution + this one
Further reading
- More about context switches
- Avoid too much indirect switch costs, YouTube video by a Google Engineer